Published on CVPR 2022
作者在这篇文章中主打的一个点是:
relations among samples from the same class and similar-looking samples from different classes, must be helpful for understanding class-discriminative visual semantics, leading to improved feature learning
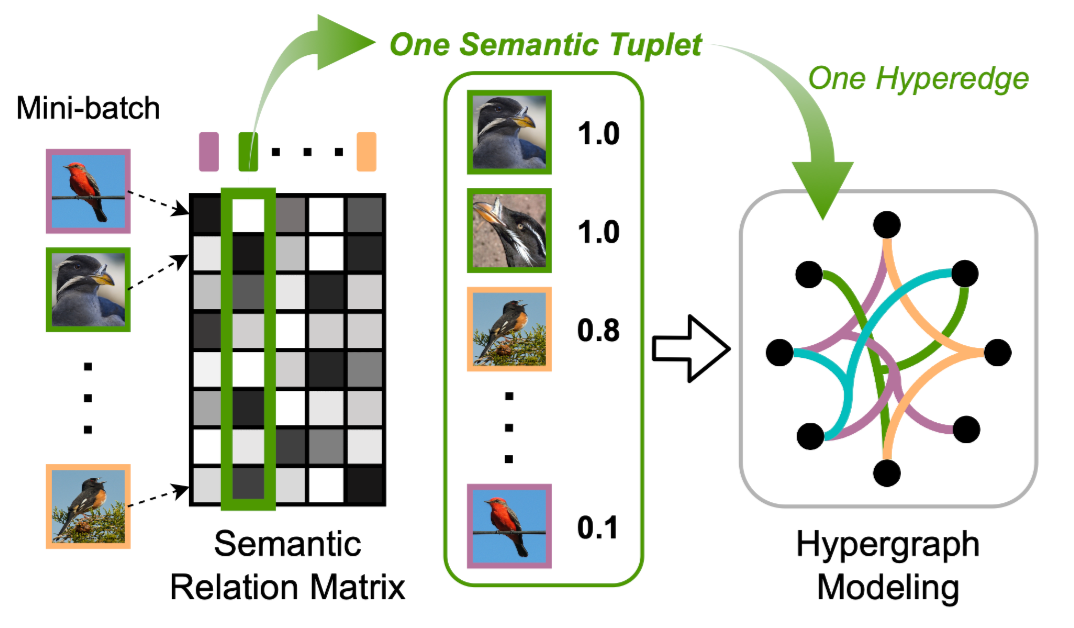
所以要考虑到一个样本同时和不同的类别有联系。比如对于鸟类识别任务来说,这种任务是比较精细的任务,粗略来说都是识别鸟,每个类别之间是有联系的,类别之间可能会有相似的样本。这是一种多边关系(multilateral relations),而超图正好可以建模这种任务。
相关工作
目前已有的度量学习损失函数一种有4类:
- Pair-based losses
- Proxy-based losses
- Classification-based losses
- Graph-based losses
这里每一类的相关工作还需要进一步看论文,先在这挖个坑。
Formulation
假设现在有$N$张图片$\mathcal{X}=\left\lbrace \mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_N\right\rbrace $ ,和对应的标签 $\mathcal{Y}=\left\lbrace y_1, y_2, \cdots, y_N\right\rbrace $,共有$C$类,$y_i \in\lbrace 1,2, \cdots, C\rbrace $。对于输入图片$\mathbf{x}_i$,有编码器$E$将其映射为$\mathbf{z}_i \in \mathbb{R}^D$:
\[\mathbf{z}_i=E\left(\mathbf{x}_i ; \boldsymbol{\Theta}\right)\]本文的目标是训练$E$使其产生有判别力的embedding。在接下来的算法设计里面,我们考虑的是一个由$N_b$个样本和标签组成的mini-batch $\mathcal{B}=\left\lbrace \left(\mathbf{x}_i, y_i\right)\right\rbrace _{i=1}^{N_b}$, $\mathcal{C} \subset\lbrace 1,2, \cdots, C\rbrace $ 表示 mini-batch $\mathcal{B}$ 的标签集合。
然后我们定义原型分布(prototypical distributions),$\mathbb{D}=\left\lbrace \mathcal{D}_1, \mathcal{D}_2, \cdots, \mathcal{D}_C\right\rbrace $表示一组可学习的分布,共有$C$个,我们希望它能建模真实的特征分布。每一类的分布$\mathcal{D}_c$有两个参数,分别是均值 $\boldsymbol{\mu}_c \in \mathbb{R}^D$ 和协方差 $\mathbf{Q}_c \in \mathbb{R}^{D \times D}$, 分别表示类簇中心和类内的variations。为了计算上的简化,这里的$\mathbf{Q}_c$是对角矩阵,对角元是$\mathbf{q}_c\in \mathbb{R}^D$, $\mathbf{Q}_c=\operatorname{diag}\left(\mathbf{q}_c\right)$. 因此 $\mathbb{D}$ 中的所有参数可以表示为 $\boldsymbol{\Phi}=\left\lbrace \left(\boldsymbol{\mu}_c, \mathbf{q}_c\right)\right\rbrace _{c=1}^C$。
然后可以定义分布损失$\mathcal{L}_D$。首先利用平方Mahalanobis距离计算样本$\mathbf{z}_i$和分布$\mathcal{D}_c$之间的距离:
\[d_m^2\left(\mathbf{z}_i, \mathcal{D}_c\right)=\left(\mathbf{z}_i-\boldsymbol{\mu}_c\right)^{\top} \mathbf{Q}_c^{-1}\left(\mathbf{z}_i-\boldsymbol{\mu}_c\right)\]基于此,可以定义$\mathbf{z}_ i$在其正确的原型分布$\mathcal{D}_+$上的概率:
\[P_i=\frac{\exp \left(-\tau d_m^2\left(\mathbf{z}_i, \mathcal{D}_{+}\right)\right)}{\sum_{\mathcal{D}_c \in \mathbb{D}} \exp \left(-\tau d_m^2\left(\mathbf{z}_i, \mathcal{D}_c\right)\right)}\]所以最终的损失可以写成所有样本的负对数似然的形式:
\[\mathcal{L}_D=\frac{1}{N_b} \sum_{i=1}^{N_b}-\log P_i\]我觉得这里有一个独特的地方是原型分布的均值$\boldsymbol{\mu}_c$是直接学出来的,而不是通过求平均值得到的。
随后对于mini-batch $\mathcal{B}$中的每一类$c \in \mathcal{C}$构建一个语义元组(semantic tuplet)$\mathcal{S}(c)$ ,总共有$|\mathcal{C}|$个,基于原型分布$\mathbb{D}$, 语义元组可以表示为矩阵的形式 $\mathbf{S} \in[0,1]^{N_b \times|\mathcal{C}|}$:
\[\mathbf{S}_{i j}=\left\lbrace \begin{array}{cc} 1 & \text { if } y_i=\mathcal{C}_j \\ e^{-\alpha d_m^2\left(\mathbf{z}_i, \mathcal{D}_{\mathcal{C}_j}\right)} & \text { otherwise } \end{array}\right.\]可以看到,当$\boldsymbol{S}_{ij}$不为1时,这可以看作是负样本的惩罚力度,越大说明就要去增加对这个样本的优化力度。此时从超图的角度来说,矩阵$\boldsymbol{S} _{ij}$可以看作是超图上节点和边之间的关系。超图上的一个超边对应于这里的一个语义元组。
然后作者用超图神经网络(Hypergraph Neural Network,HGNN)在这个构建出来的超图上进行学习,然后做一个节点分类任务。超图第$l+1$层的输出计算如下:
\[\mathbf{Z}^{(l+1)}=\sigma\left(\mathbf{D}_v^{-\frac{1}{2}} \mathbf{H D}_e^{-1} \mathbf{H}^{\top} \mathbf{D}_v^{-\frac{1}{2}} \mathbf{Z}^{(l)} \mathbf{\Psi}^{(l)}\right)\]$\boldsymbol{\Psi}^{(l)} \in \mathbb{R}^{d_l \times d_{l+1}}$ 表示网络权重,$\boldsymbol{H}$便是这里的$\boldsymbol{S}$,$\mathbf{D}_v$和$\mathbf{D}_e$分别是节点和边的度矩阵。最后一层的输出经过softmax函数得到类别概率,随后计算和真实标签的交叉熵:
\[\hat{\mathbf{Y}}=\operatorname{softmax}\left(\mathbf{Z}^{(L)}\right)\\ \mathcal{L}_{C E}=-\frac{1}{N_b} \sum_{i=1}^{N_b} \sum_{j=1}^C \mathbf{Y}_{i j} \log \hat{\mathbf{Y}}_{i j}\]最终模型的损失函数是原型分布的损失和交叉熵损失的加权求和:
\[\mathcal{L}_{\text {hist }}=\mathcal{L}_D+\lambda_s \mathcal{L}_{C E}\]模型的框架图如下:
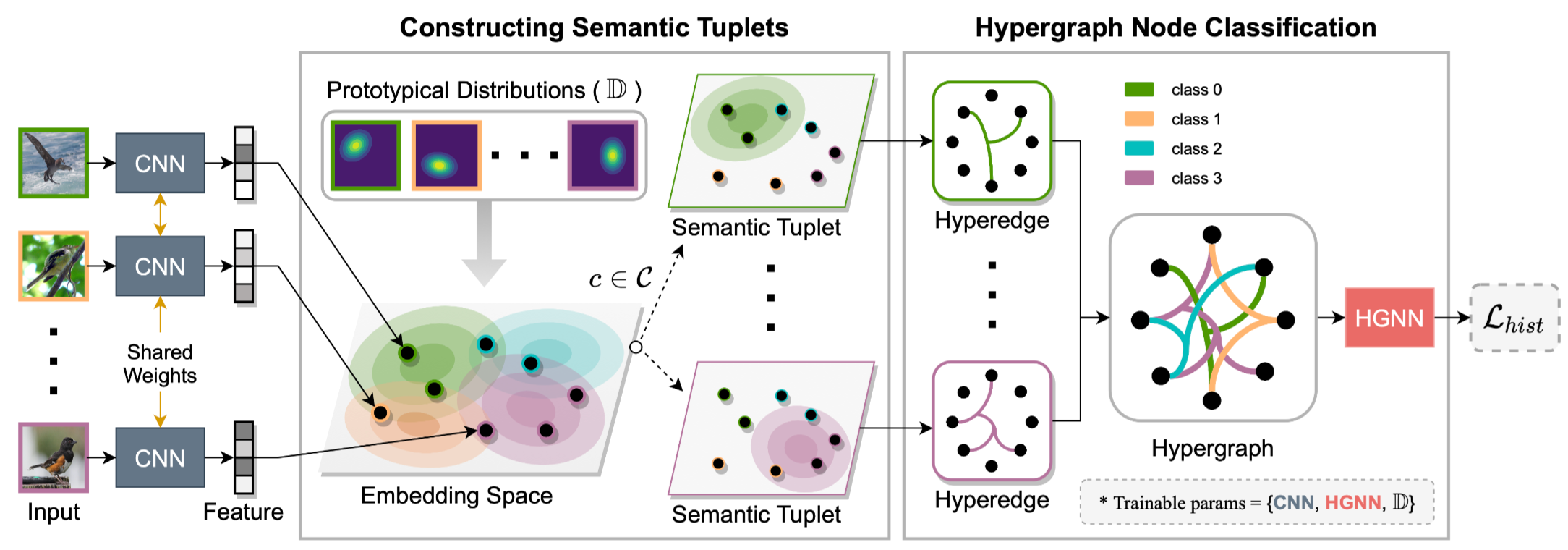
作者在分析模型框架的合理性时指出,由于超图会使得同一超边里面的样本更加相似,所以为了区分同一超边里面的正样本和误入的负样本,该模型会强迫CNN学习更加有判别性的特征,而不是背景或者噪声信息,这使得学到的特征更具有鲁棒性。
实验
在实验部分的激活图挺有意思的:
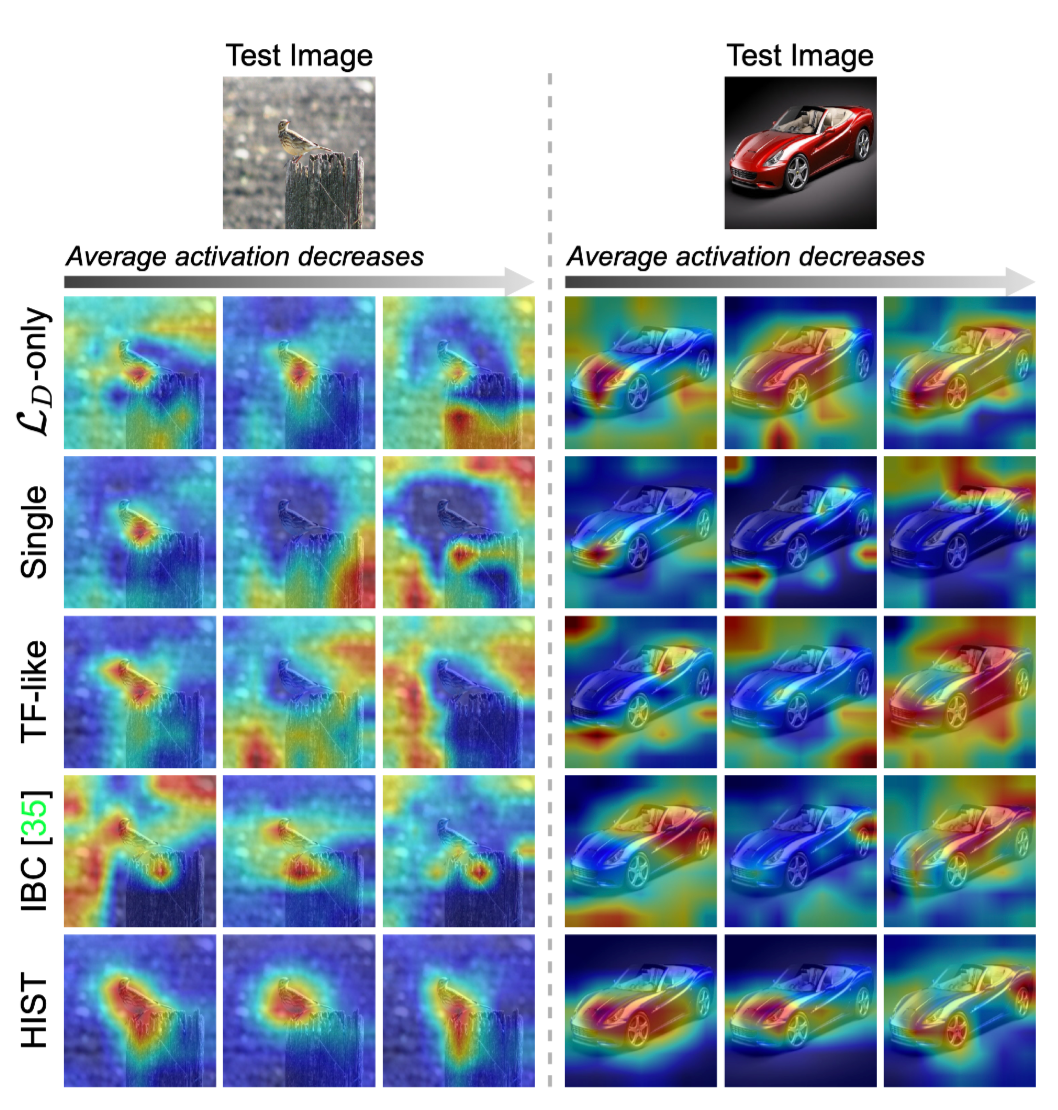
作者讲最后一层卷积层中通道的平均激活值从大到小排序,选出了top-3通道。从结果可以看到,本文提出的HIST使得特征更加集中在目标区域,而且通道有分工,比如那个汽车的图片,有的集中在车前盖,有的集中在车轮,这种通道具有语义信息。其他方法并没有本文的那么显著,有些都集中在背景信息。所以说本文提出的这个方法确实是可以提升模型的特征提取能力,embedding的判别能力,而且更加鲁棒。
-
Previous
Metric learning with adaptive density discrimination -
Next
Multi-level Distance Regularization for Deep Metric Learning