Published on AAAI 2021
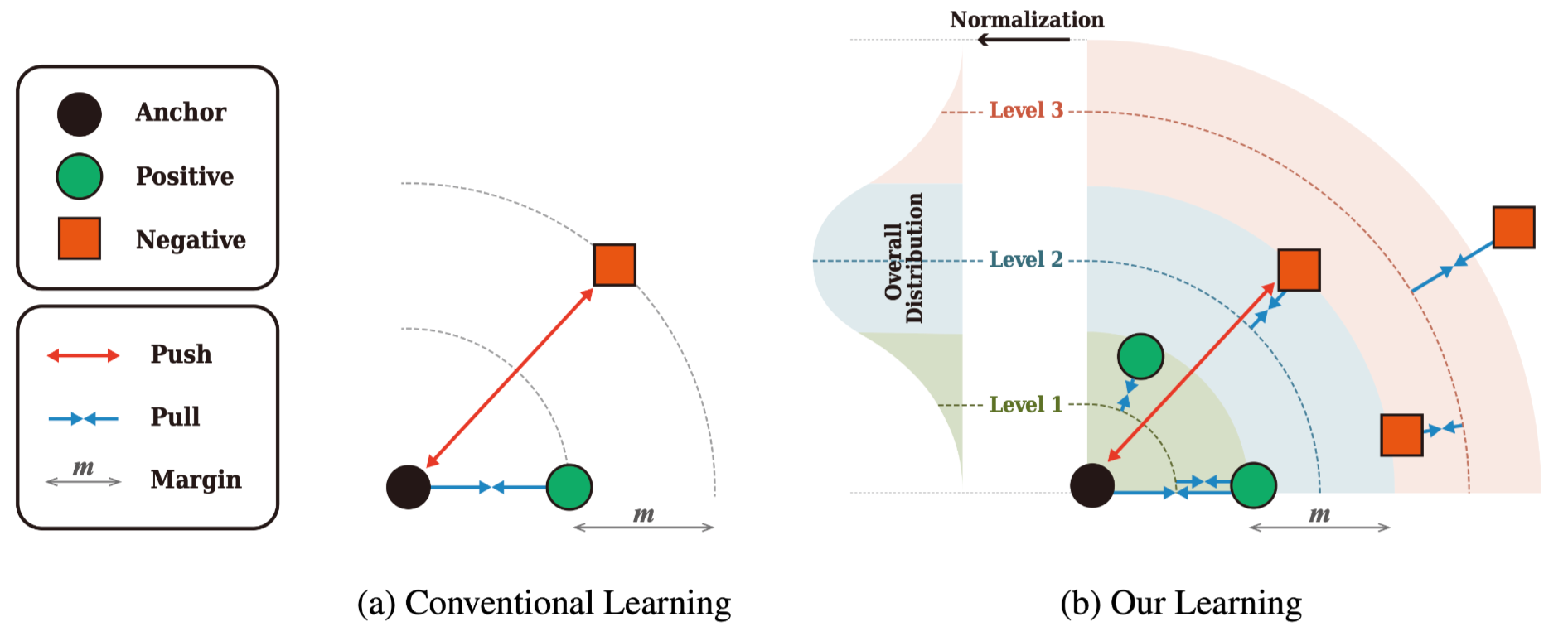
本文提出了一种用于深度度量学习的新的基于距离的正则化方法,称为Multi-level Distance Regularization (MDR)。它能够让表征空间中向量之间的距离归属于不同的level,以表示样本对之间不同程度的相似性。在训练过程中,这种多层级的设计能够阻止样本被忽视(因为样本太简单了)或者被过度注意(因为样本太难了),这使得参数的优化过程更加平稳,同时提升了模型的泛化能力。
下图是本文的损失和Triplet loss的对比:
Formulation
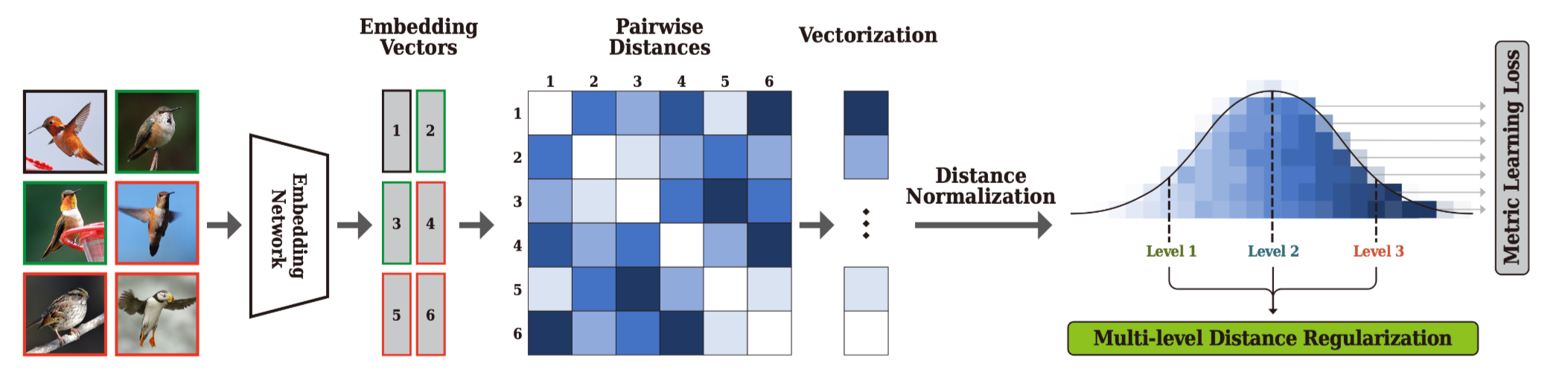
本文提出的Multi-level Distance Regularization(MDR)可以分成3步。
1. Distance Normalization
对于输入图片$x$,编码网络 $f$ 将其映射为表征向量 $e$:
\[e=f(x)\]可以基于欧式距离定义两个表征向量之间的距离:
\[d\left(e_i, e_j\right)=\left\|e_i-e_j\right\|_2\]然后对距离进行标准化:
\[\bar{d}\left(e_i, e_j\right)=\frac{d\left(e_i, e_j\right)-\mu}{\sigma}\]基于样本对的集合$\mathcal{P}=\left\lbrace\left(e_i, e_j\right) \mid i \neq j\right\rbrace$ ,$\mu$是距离的均值,$\sigma$是距离的标准差。为了考虑到整个数据集,均值和标准差的更新可以采用动量更新的方式:
\[\begin{aligned} \mu_t^* &=\gamma \mu_{t-1}^*+(1-\gamma) \mu \\ \sigma_t^* &=\gamma \sigma_{t-1}^*+(1-\gamma) \sigma \end{aligned}\]此时标准化之后的距离可以写成:
\[\bar{d}\left(e_i, e_j\right)=\frac{d\left(e_i, e_j\right)-\mu^*}{\sigma^*} .\]2. Level Assignment
MDR将不同的level作为标准化之后的距离的正则化目标。预先定义一个level的集合$s\in\mathcal{S}$,集合里面的level值初始化为预先定义的数值,比如$\mathcal{S}=\lbrace-3,0,3\rbrace$。每个level $s$可以理解成对距离标准差的乘数。$g(d;s)$是一个指示函数,用来判断是否某个距离 $d$ 与给定的level $s$ 是最近的:
\[g(d, s)= \begin{cases}1, & \text { if } \arg \min _{s_i \in \mathcal{S}}\left|d-s_i\right| \text { is } s \\ 0, & \text { otherwise }\end{cases}\]3. Regularization
最终的损失函数定义如下:
\[\mathcal{L}_{\mathrm{MDR}}=\frac{1}{\mathcal{P}} \sum_{\left(e_i, e_j\right) \in \mathcal{P}} \sum_{s \in \mathcal{S}} g\left(\bar{d}\left(e_i, e_j\right), s\right) \cdot\left|\bar{d}\left(e_i, e_j\right)-s\right| .\]这里的level $s$ 是可学习的参数,作者在实验中尝试了对level set不同的初始化,发现$\lbrace-3,0,3\rbrace$是一个比较好的初始化。可以看到,这个在计算损失的时候,如果$e_i,e_j$之间的距离不属于某个特定的level,则不计算之间的距离和level之间的损失,计算的是距离最近的level之间的损失。
这个损失函数有两个作用:
- 与之间对两个样本之间距离进行优化的方法相比,这种对距离的多层次分配使得优化变得更加复杂,这就防止模型在训练集上产生过拟合。
- 最外边的level阻止了和正样本对之间变得更近,和负样本对之间变得更远。这提升了学习难度,使得训练过程更加平稳,对简单的样本loss下降不会太快,也不会太偏向于困难的样本。
在最终学习时的损失函数可以用任意的深度度量学习函数和本文提出的MDR组合:
\[\mathcal{L}=\mathcal{L}_{\mathrm{DML}}+\lambda \mathcal{L}_{\mathrm{MDR}} .\]下图是模型的框架图:
Embedding Normalization Trick for MDR
作者提到,$L_2$ norm会扰乱MDR的正则化效果,但是为了对参数进行约束,文章中对$\mathcal{L}_{DML}$进行标准化,即对表征向量除以$\mu$,使得:
\[\mathbb{E}\left[d\left(\frac{e_i}{\mu}, \frac{e_j}{\mu}\right)\right]=1\]实验
模型在训练和测试集上的学习曲线如下:
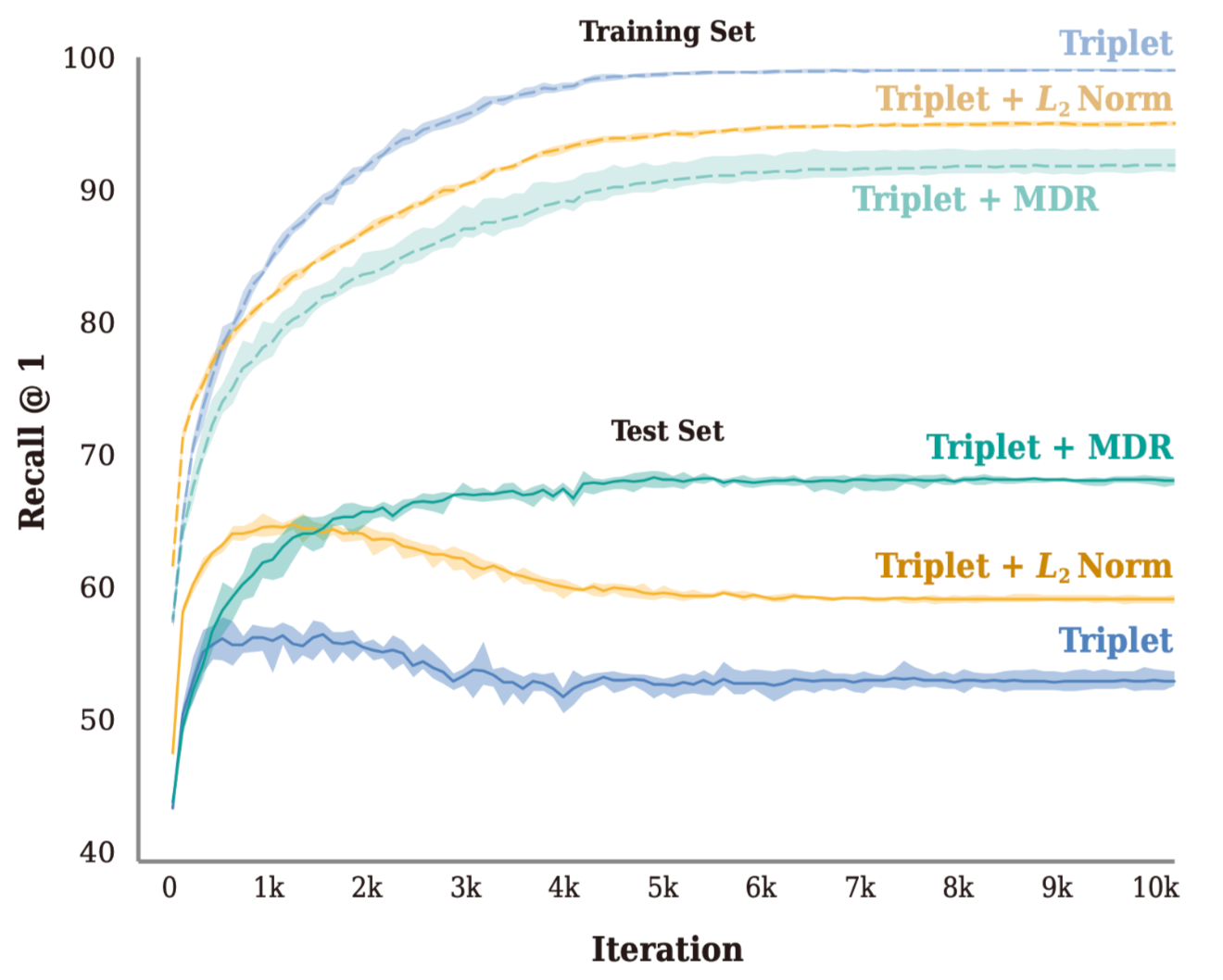
可以看到除了MDR之外的其他两种方法都在训练集上过拟合了,使得其在测试集上的效果下降。
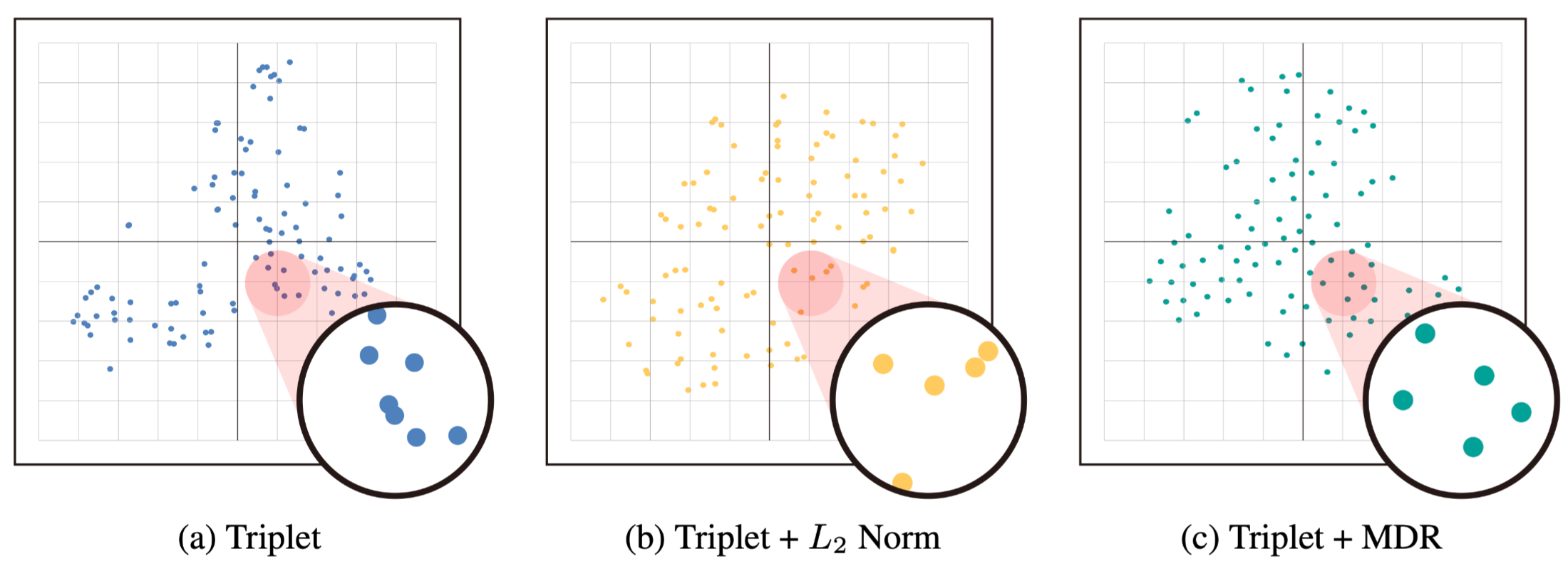
下面这张图可视化了类中心,可以看到MDR方法学到的类中心间距更均匀,距离更大。
下图是不同level的图片展示:
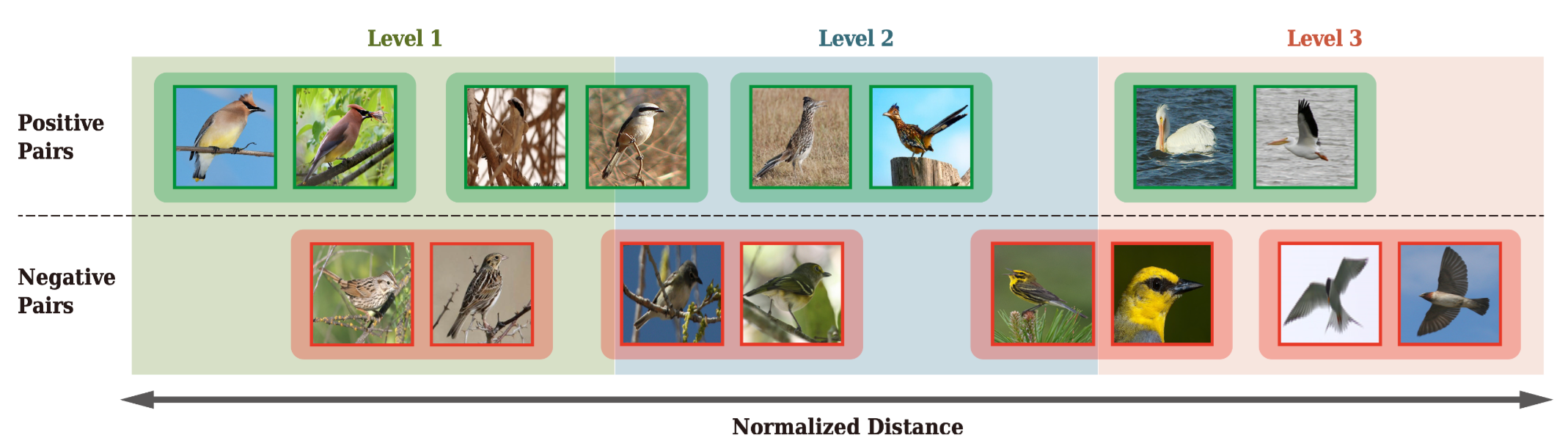
可以看到正样本对主要分布在level 1和level 2,负样本对主要分布在level 2和level 3。但是也有hard-positive pairs属于level 3,hard-negative pairs属于 level 1。可以看到,在这里的训练过程中,不在是那种binary supervision主导训练,而是level占主导。这就提升了模型的泛化能力。
-
Previous
Hypergraph-Induced Semantic Tuplet Loss for Deep Metric Learning -
Next
GNNExplainer: Generating Explanations for Graph Neural Networks